Database, Data Mining And Data Warehouse
What is Database?
Think of the first thing when you hear the word “DataBase”. People generally think of “database” as the place where all the data are stored. In the tech world, database not only stores the data but also provides a lot of functionalities on top of the stored data. The features can be tracking the changes in the data, querying the database, updating and modifying the data, etc.
Think of your storage in your computer as a database. The storage contains your documents, images, applications and more files. You can view and open the file; you can modify the file in one way or other. You can transfer it from a device or a location to another. This is similar to what we are talking about.
The only difference I can tell as far as I know is the database only store textual value (string, numbers, booleans and more) in certain structure/format. Now the question may arise: Where are the images, audio and videos file (non-textual files) stored? The simple answer to this is: Since the database only stores the textual value, the database stores the location (URL) of the non-textual files and the actual files are stored in the server which can be directly accessed from the provided URL.
Let’s discuss how the data are actually stored: The two most common approaches of storing data in the database is table and document.
As we know, the table like in Excel contains rows and columns. The actual data is stored in the cells (intersection of rows and columns) similar to Excel. In this approach of the database, the table is also known as relation. A single database (say College) is a collection of multiple related (having relation like one-one, one-many, many-many) tables (like Students, Teachers, Staffs, Library and more).
For purpose of normalization and less data duplication (redundancy), the tables are related to each other with a key known as foreign key. Each row should have a unique id/ value for its unique identification with use of primary key (can’t be null or repetitive).

Unlike a table, a document has multiple related key-value pairs on it. Each key represents an attribute and value holds the actual information. Documents are not linked/related with each other, which helps for better query performance. Since the data values (table) are linked to each other as a chain, you might need to keep on jumping till the required value is found.
In broader view, both tables and documents represents an actual real world object with its list of attributes and their corresponding values. Their method of representation may vary, but they both are equally used and popular method of database.
What is Data Mining ?
OK, we have got the data in the database. Where do we go now?
You probably might have heard people say that data is money. OK, you got the data; where is the money? That is where data mining comes into the play.
Not every data is money; only useful and relevant data are. You have a huge chunk of data, but how do you actually determine which data are useful? You consider the domain or subject you are working on.
For e.g. If you are working on sales, you might need data of products, customers, suppliers, etc, but you don’t need data of staffs, customer care, etc. It is important to remember that you set the boundary between useful and useless data for a given specific domain.
What actually is data mining? Data mining is the process of discovering knowledge, insights and patterns from given pre-processed data which is done on top of the actual database. Data mining is a vast topic in itself. It has been in use since decades, but its rise really went nuts due to sudden growth of AI (Artificial Intelligence) and ML (Machine Learning).
Let’s get to know the basic implementation of the data mining:
1. Understand your subject and domain
Before starting your data mining, you need to clearly understand and define the end goals for your data mining tasks that lead you and your company to success. What is the current scenario? What do you want the future scenario to be? And always remember that the mining is done for specific domain only.
2. Understand your data
In this step, you need to understand the structure and format of your stored data. What are the data sources? Is data integration from multiple sources necessary? What should the final data look like? How complete and relevant your data is?
3. Prepare the Data
This step is also known as data pre-processing. In this step, tasks like data integration from multiple sources, data reduction, data transformation, data cleaning and selection, etc are done to prepare the data ready to be fed to the data mining engine which applies the various algorithms to the fed data.
4. Build the Model
Based on the type and volume of your data and need, construct a data mining model that takes pre-processed data as input and returns patterns and insights as output. The model is said to be efficient if its accuracy and efficiency is above or equal to 93%. The huge volume of training data is fed to the model to improve its accuracy. Algorithms can be optimized to improve its speed.
5. Evaluate the Results
After the model is created, it is time to test those model. For this case, test data is necessary to test the characteristics of the model (efficiency, accuracy, speed, scalability and more).
6. Deploy and Monitor
After the model is ready for production level, deploy it and keep track of its activities (progress and errors) to constantly upgrade it.
What is Data Warehouse?

How inconvenient do you think querying the database each time for data mining task ? Maybe not much for you, but it sure will take a lot of resources out of your system. It is very resource intensive (Querying may not seem resource intensive at a glance, but it sure is, especially in RDBMS).
Even though it is better to keep our database normalized, it is not the same for the data warehouse. Data warehouse is the storage for storing denormalized, complete, accurate and pre-processed data required for data mining tasks.
If you have the database, why do you need a data warehouse?
Our data mining tasks should not be capable of modifying the actual data in the database. Past records must not be tampered at any cost. The database indirectly supports the data mining, as the data warehouse is built on top of the database.
We have already talked about the performance and resource issues above resolved by de-normalized data warehouse. Furthermore, data warehouse is subject specific while database is organization specific. Data warehouse also tracks the similar past data mining issues, solution and methodologies.
How Data Warehouse Works
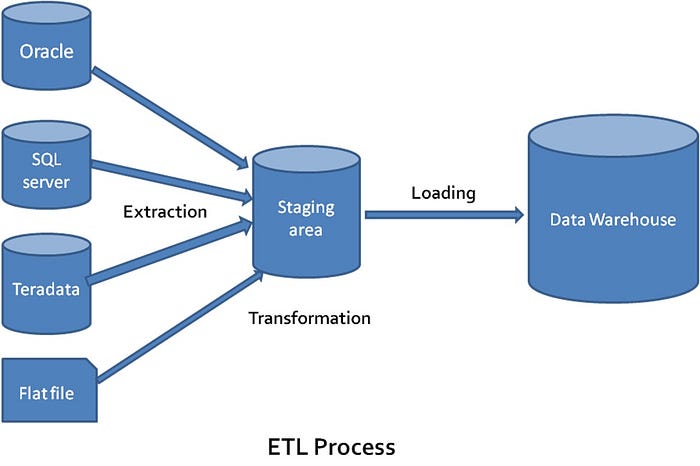
- Extraction: Necessary data is extracted from multiple sources (web, files, databases) and integrated into a single place.
- Pre-processing: Pre-processing is done on the integrated data to maintain data quality.
- Data loading: Pre-processed data is loaded and stored in data warehouse.
- Data analysis: After data is loaded, analysis can be done on the data with help of tools like BI (Business intelligence) tools, SQL clients and other analysis tools.
Features of Data Warehouse
- Subject oriented: Data warehouse is always built around certain subject.
- Non-volatile : Data warehouse is not updated or deleted for purpose of historical analysis.
- Time-variant: Data inside warehouse are stored over time for historical analysis and future references.
- Integrated: Data stored in warehouses are integrated from multiple sources.
Benefits of Data Warehouse
- Improved decision-making: Data warehouse allows us to make better and informed decision based on the factual data.
- Increased efficiency : Warehouse saves time and resources.
- Improved data quality: Before storing data in warehouse, pre-processing is a must, which ensures data consistency and reliability.
- Enhanced data analysis: Since all relevant data is stored in a single place, it is easy to use analysis tools to deduce and draw conclusions from the data.
